Abstract (tl;dr)
We’re getting some bad home Internet service from Alaska Communications, and it’s getting worse. There are clear patterns indicating lower quality service in the evening, and very poor download rates over the past couple days. Scroll down to check out the plots.
Introduction
Over the past year we’ve started having trouble watching streaming video over our Internet connection. We’re paying around $100/month for phone, long distance and a 4 Mbps DSL Internet connection, which is a lot of money if we’re not getting a quality product. The connection was pretty great when we first signed up (and frankly, it’s better than a lot of people in Fairbanks), but over time, the quality has degraded and despite having a technician out to take a look, it hasn’t gotten better.
Methods
In September last year I started monitoring our bandwidth, once every two hours, using the Python speedtest-cli tool, which uses speedtest.net to get the data.
To use it, install the package:
$ pip install speedtest-cli
Then set up a cron job on your server to run this once every two hours. I have it running on the raspberry pi that collects our weather data. I use this script, which appends data to a file each time it is run. You’ll want to change the server to whichever is closest and most reliable at your location.
#! /bin/bash
results_dir="/path/to/results"
date >> ${results_dir}/speedtest_results
speedtest --server 3191 --simple >> ${results_dir}/speedtest_results
The raw output file just keeps growing, and looks like this:
Mon Sep 1 09:20:08 AKDT 2014 Ping: 199.155 ms Download: 2.51 Mbits/s Upload: 0.60 Mbits/s Mon Sep 1 10:26:01 AKDT 2014 Ping: 158.118 ms Download: 3.73 Mbits/s Upload: 0.60 Mbits/s ...
This isn’t a very good format for analysis, so I wrote a Python script to process the data into a tidy data set with one row per observation, and columns for ping time, download and upload rates as numbers.
From here, we can look at the data in R. First, let’s see how our rates change during the day. One thing we’ve noticed is that our Internet will be fine until around seven or eight in the evening, at which point we can no longer stream video successfully. Hulu is particularly bad at handling a lower quality connection.
Code to get the data and add some columns to group the data appropriately for plotting:
#! /usr/bin/env Rscript
# Prep:
# parse_speedtest_results.py speedtest_results speedtest_results.csv
library(lubridate)
library(ggplot2)
library(dplyr)
speed <- read.csv('speedtest_results.csv', header=TRUE) %>%
tbl_df() %>%
mutate(date=ymd_hms(as.character(date)),
yyyymm=paste(year(date), sprintf("%02d", month(date)), sep='-'),
month=month(date),
hour=hour(date))
Plot it:
q <- ggplot(data=speed, aes(x=factor(hour), y=download)) +
geom_boxplot() +
scale_x_discrete(name="Hour of the day") +
scale_y_continuous(name="Download speed (Mbps)") +
ggtitle(paste("Speedtest results (",
min(floor_date(speed$date, "day")), " - " ,
max(floor_date(speed$date, "day")), ")", sep="")) +
theme_bw() +
facet_wrap(~ yyyymm)
Results and Discussion
Here’s the result:
Box and whisker plots (boxplots) show how data is distributed. The box represents the range where half the data lies (from the 25th to the 75th percentile) and the line through the box represents the median value. The vertical lines extending above and below the box (the whiskers), show where most of the rest of the observations are, and the dots are extreme values. The figure above has a single boxplot for each two hour period, and the plots are split into month-long periods so we can see if there are any trends over time.
There are some clear patterns across all months: our bandwidth is pretty close to what we’re paying for for most of the day. The boxes are all up near 4 Mbps and they’re skinny, indicating that most of the observations are close to 4 Mbps. Starting in the early evening, the boxes start getting larger, demonstrating that we’re not always getting our expected rate. The boxes are very large between eight and ten, which means we’re as likely to get 2 Mbps as the 4 we pay for.
Patterns over time are also showing up. Starting in January, there’s another drop in our bandwidth around noon and by February it’s rare that we’re getting the full speed of our connection at any time of day.
One note: it is possible that some of the decline in our bandwidth during the evening is because the download script is competing with the other things we are doing on the Internet when we are home from work. This doesn’t explain the drop around noon, however, and when I look at the actual Internet usage diagrams collected from our router using SMTP / MRTG, it doesn’t appear that we are really using enough bandwidth to explain the dramatic and consistent drops seen in the plot above.
February is starting to look different from the other months, I took a closer look at the data for that month. I’m filtering the data to just February, and based on a look at the initial version of this plot, I added trend lines for the period before and after noon on the 12th of February.
library(dplyr)
library(lubridate)
library(ggplot2)
library(scales)
speeds <- tbl_df(read.csv('speedtest_results.csv', header=TRUE))
speed_plot <-
speeds %>%
mutate(date=ymd_hms(date),
grp=ifelse(date<'2015-02-12 12:00:00', 'before', 'after')) %>%
filter(date > '2015-01-31 23:59:59') %>%
ggplot(aes(x=date, y=download)) +
geom_point() +
theme_bw() +
geom_smooth(aes(group=grp), method="lm", se=FALSE) +
scale_y_continuous(limits=c(0,4.5),
breaks=c(0,1,2,3,4),
name="Download speed (Mbps)") +
theme(axis.title.x=element_blank())
The result:
Ouch. Throughout the month our bandwidth has been going down, but you can also see that after noon on the 12th, we’re no longer getting 4 Mpbs no matter what time of day it is. The trend line probably isn’t statistically significant for this period, but it’s clear that our Internet service, for which we pay a lot of money for, is getting worse and worse, now averaging less than 2 Mbps.
Conclusion
I think there’s enough evidence here that we aren’t getting what we are paying for from our ISP. Time to contact Alaska Communications and get them to either reduce our rates based on the poor quality of service they are providing, or upgrade their equipment to handle the traffic on our line. I suspect they probably oversold the connection and the equipment can’t handle all the users trying to get their full bandwidth at the same time.

How will I do?
My last blog post compared the time for the men who ran both the 2012 Gold Discovery Run and the Equinox Marathon in order to give me an idea of what sort of Equinox finish time I can expect. Here, I’ll do the same thing for the 2012 Santa Claus Half Marathon.
Yesterday I ran the half marathon, finishing in 1:53:08, which is an average pace of 8.63 / 8:38 minutes per mile. I’m recovering from a mild calf strain, so I ran the race very conservatively until I felt like I could trust my legs.
I converted the SportAlaska PDF files the same way as before, and read the data in from the CSV files. Looking at the data, there are a few outliers in this comparison as well. In addition to being ouside of most of the points, they are also times that aren’t close to my expected pace, so are less relevant for predicting my own Equinox finish. Here’s the code to remove them, and perform the linear regression:
combined <- combined[!(combined$sc_pace > 11.0 | combined$eq_pace > 14.5),]
model <- lm(eq_pace ~ sc_pace, data=combined)
summary(model)
Call:
lm(formula = eq_pace ~ sc_pace, data = combined)
Residuals:
Min 1Q Median 3Q Max
-1.08263 -0.39018 0.02476 0.30194 1.27824
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.11209 0.61948 -1.795 0.0793 .
sc_pace 1.44310 0.07174 20.115 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.5692 on 45 degrees of freedom
Multiple R-squared: 0.8999, Adjusted R-squared: 0.8977
F-statistic: 404.6 on 1 and 45 DF, p-value: < 2.2e-16
There were fewer male runners in 2012 that ran both Santa Claus and Equinox, but we get similar regression statistics. The model and coefficient are significant, and the variation in Santa Claus pace times explains just under 90% of the variation in Equinox times. That’s pretty good.
Here’s a plot of the results:
As before, the blue line shows the model relationship, and the grey area surrounding it shows the 95% confidence interval around that line. This interval represents the range over which 95% of the expected values should appear. The red line is the 1:1 line. As you’d expect for a race twice as long, all the Equinox pace times are significantly slower than for Santa Claus.
There were fewer similar runners in this data set:
| Runner | DOB | Santa Claus | Equinox Time | Equinox Pace |
|---|---|---|---|---|
| John Scherzer | 1972 | 8:17 | 4:49 | 11:01 |
| Greg Newby | 1965 | 8:30 | 5:03 | 11:33 |
| Trent Hubbard | 1972 | 8:31 | 4:48 | 11:00 |
This analysis predicts that I should be able to finish Equinox in just under five hours, which is pretty close to what I found when using Gold Discovery times in my last post. The model predicts a pace of 11:20 and an Equinox finish time of four hours and 57 minutes, and these results are within the range of the three similar runners listed above. Since I was running conservatively in the half marathon, and will probably try to do the same for Equinox, five hours seems like a good goal to shoot for.

Gold Discovery Run, 2013
This spring I ran the Beat Beethoven 5K and had such a good time that I decided to give running another try. I’d tried adding running to my usual exercise routines in the past, but knee problems always sidelined me after a couple months. It’s been three months of slow increases in mileage using a marathon training plan by Hal Higdon, and so far so good.
My goal for this year, beyond staying healthy, is to participate in the 51st running of the Equinox Marathon here in Fairbanks.
One of the challenges for a beginning runner is how pace yourself during a race and how to know what your body can handle. Since Beat Beethoven I've run in the Lulu’s 10K, the Midnight Sun Run (another 10K), and last weekend I ran the 16.5 mile Gold Discovery Run from Cleary Summit down to Silver Gulch Brewery. I completed the race in two hours and twenty-nine minutes, at a pace of 9:02 minutes per mile. Based on this performance, I should be able to estimate my finish time and pace for Equinox by comparing the times for runners that participated in the 2012 Gold Discovery and Equinox.
The first challenge is extracting the data from the PDF files SportAlaska publishes after the race. I found that opening the PDF result files, selecting all the text on each page, and pasting it into a text file is the best way to preserve the formatting of each line. Then I process it through a Python function that extracts the bits I want:
import re
def parse_sportalaska(line):
""" lines appear to contain:
place, bib, name, town (sometimes missing), state (sometimes missing),
birth_year, age_class, class_place, finish_time, off_win, pace,
points (often missing) """
fields = line.split()
place = int(fields.pop(0))
bib = int(fields.pop(0))
name = fields.pop(0)
while True:
n = fields.pop(0)
name = '{} {}'.format(name, n)
if re.search('^[A-Z.-]+$', n):
break
pre_birth_year = []
pre_birth_year.append(fields.pop(0))
while True:
try:
f = fields.pop(0)
except:
print("Warning: couldn't parse: '{0}'".format(line.strip()))
break
else:
if re.search('^[0-9]{4}$', f):
birth_year = int(f)
break
else:
pre_birth_year.append(f)
if re.search('^[A-Z]{2}$', pre_birth_year[-1]):
state = pre_birth_year[-1]
town = ' '.join(pre_birth_year[:-1])
else:
state = None
town = None
try:
(age_class, class_place, finish_time, off_win, pace) = fields[:5]
class_place = int(class_place[1:-1])
finish_minutes = time_to_min(finish_time)
fpace = strpace_to_fpace(pace)
except:
print("Warning: couldn't parse: '{0}', skipping".format(
line.strip()))
return None
else:
return (place, bib, name, town, state, birth_year, age_class,
class_place, finish_time, finish_minutes, off_win,
pace, fpace)
The function uses a a couple helper functions that convert pace and time strings into floating point numbers, which are easier to analyze.
def strpace_to_fpace(p):
""" Converts a MM:SS" pace to a float (minutes) """
(mm, ss) = p.split(':')
(mm, ss) = [int(x) for x in (mm, ss)]
fpace = mm + (float(ss) / 60.0)
return fpace
def time_to_min(t):
""" Converts an HH:MM:SS time to a float (minutes) """
(hh, mm, ss) = t.split(':')
(hh, mm) = [int(x) for x in (hh, mm)]
ss = float(ss)
minutes = (hh * 60) + mm + (ss / 60.0)
return minutes
Once I process the Gold Discovery and Equnox result files through this routine, I dump the results in a properly formatted comma-delimited file, read the data into R and combine the two race results files by matching the runner’s name. Note that these results only include the men competing in the race.
gd <- read.csv('gd_2012_men.csv', header=TRUE)
gd <- gd[,c('name', 'birth_year', 'finish_minutes', 'fpace')]
eq <- read.csv('eq_2012_men.csv', header=TRUE)
eq <- eq[,c('name', 'birth_year', 'finish_minutes', 'fpace')]
combined <- merge(gd, eq, by='name')
names(combined) <- c('name', 'birth_year', 'gd_finish', 'gd_pace',
'year', 'eq_finish', 'eq_pace')
When I look at a plot of the data I can see four outliers; two where the runners ran Equinox much faster based on their Gold Discovery pace, and two where the opposite was the case. The two races are two months apart, so I think it’s reasonable to exclude these four rows from the data since all manner of things could happen to a runner in two months of hard training (or on race day!).
attach(combined)
combined <- combined[!((gd_pace > 10 & gd_pace < 11 & eq_pace > 15)
| (gd_pace > 15)),]
Let’s test the hypothesis that we can predict Equinox pace from Gold Discovery Pace:
model <- lm(eq_pace ~ birth_year, data=combined)
summary(model)
Call:
lm(formula = eq_pace ~ gd_pace, data = combined)
Residuals:
Min 1Q Median 3Q Max
-1.47121 -0.36833 -0.04207 0.51361 1.42971
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.77392 0.52233 1.482 0.145
gd_pace 1.08880 0.05433 20.042 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.6503 on 48 degrees of freedom
Multiple R-squared: 0.8933, Adjusted R-squared: 0.891
F-statistic: 401.7 on 1 and 48 DF, p-value: < 2.2e-16
Indeed, we can explain 65% of the variation in Equinox Marathon pace times using Gold Discovery pace times, and both the model and the model coefficient are significant.
Here’s what the results look like:
The red line shows a relationship where the Gold Discovery pace is identical to the Equinox pace for each running. Because the actual data (and the prediced results based on the regression model) are above this line, that means that all the runners were slower in the longer (and harder) Equinox Marathon.
As for me, my 9:02 Gold Discovery pace should translate into an Equinox pace around 10:30. Here are the 2012 runners who were born within ten years of me, and who finished within ten minutes of my 2013 Gold Discovery time:
| Runner | DOB | Gold Discovery | Equinox Time | Equinox Pace |
|---|---|---|---|---|
| Dan Bross | 1964 | 2:24 | 4:20 | 9:55 |
| Chris Hartman | 1969 | 2:25 | 4:45 | 10:53 |
| Mike Hayes | 1972 | 2:27 | 4:58 | 11:22 |
| Ben Roth | 1968 | 2:28 | 4:47 | 10:57 |
| Jim Brader | 1965 | 2:31 | 4:09 | 9:30 |
| Erik Anderson | 1971 | 2:32 | 5:03 | 11:34 |
| John Scherzer | 1972 | 2:33 | 4:49 | 11:01 |
| Trent Hubbard | 1972 | 2:33 | 4:48 | 11:00 |
Based on this, and the regression results, I expect to finish the Equinox Marathon in just under five hours if my training over the next two months goes well.
Earlier today our monitor stopped working and left us without heat when it was −35°F outside. I drove home and swapped the broken heater with our spare, but the heat was off for several hours and the temperature in the house dropped into the 50s until I got the replacement running. While I waited for the house to warm up, I took a look at the heat loss data for the building.
To do this, I experimented with the “Python scientific computing stack,”: the IPython shell (I used the notebook functionality to produce the majority of this blog post), Pandas for data wrangling, matplotlib for plotting, and NumPy in the background. Ordinarily I would have performed the entire analysis in R, but I’m much more comfortable in Python and the IPython notebook is pretty compelling. What is lacking, in my opinion, is the solid graphics provided by the ggplot2 package in R.
First, I pulled the data from the database for the period the heater was off (and probably a little extra on either side):
import psycopg2
from pandas.io import sql
con = psycopg2.connect(host = 'localhost', database = 'arduino_wx')
temps = sql.read_frame("""
SELECT obs_dt, downstairs,
(lead(downstairs) over (order by obs_dt) - downstairs) /
interval_to_seconds(lead(obs_dt) over (order by obs_dt) - obs_dt)
* 3600 as downstairs_rate,
upstairs,
(lead(upstairs) over (order by obs_dt) - upstairs) /
interval_to_seconds(lead(obs_dt) over (order by obs_dt) - obs_dt)
* 3600 as upstairs_rate,
outside
FROM arduino
WHERE obs_dt between '2013-03-27 07:00:00' and '2013-03-27 12:00:00'
ORDER BY obs_dt;""", con, index_col = 'obs_dt')
SQL window functions calculate the rate the temperature is changing from one observation to the next, and convert the units to the change in temperature per hour (Δ°F/hour).
Adding the index_col attribute in the sql.read_frame() function is very important so that the Pandas data frame doesn’t have an arbitrary numerical index. When plotting, the index column is typically used for the x-axis / independent variable.
Next, calculate the difference between the indoor and outdoor temperatures, which is important in any heat loss calculations (the greater this difference, the greater the loss):
temps['downstairs_diff'] = temps['downstairs'] - temps['outside']
temps['upstairs_diff'] = temps['upstairs'] - temps['outside']
I took a quick look at the data and it looks like the downstairs temperatures are smoother so I subset the data so it only contains the downstairs (and outside) temperature records.
temps_up = temps[['outside', 'downstairs', 'downstairs_diff', 'downstairs_rate']]
print(u"Minimum temperature loss (°f/hour) = {0}".format(
temps_up['downstairs_rate'].min()))
temps_up.head(10)
Minimum temperature loss (deg F/hour) = -3.7823079517
| obs_dt | outside | downstairs | diff | rate |
|---|---|---|---|---|
| 2013-03-27 07:02:32 | -33.09 | 65.60 | 98.70 | 0.897 |
| 2013-03-27 07:07:32 | -33.19 | 65.68 | 98.87 | 0.661 |
| 2013-03-27 07:12:32 | -33.26 | 65.73 | 98.99 | 0.239 |
| 2013-03-27 07:17:32 | -33.52 | 65.75 | 99.28 | -2.340 |
| 2013-03-27 07:22:32 | -33.60 | 65.56 | 99.16 | -3.782 |
| 2013-03-27 07:27:32 | -33.61 | 65.24 | 98.85 | -3.545 |
| 2013-03-27 07:32:31 | -33.54 | 64.95 | 98.49 | -2.930 |
| 2013-03-27 07:37:32 | -33.58 | 64.70 | 98.28 | -2.761 |
| 2013-03-27 07:42:32 | -33.48 | 64.47 | 97.95 | -3.603 |
| 2013-03-27 07:47:32 | -33.28 | 64.17 | 97.46 | -3.780 |
You can see from the first bit of data that when the heater first went off, the differential between inside and outside was almost 100 degrees, and the temperature was dropping at a rate of 3.8 degrees per hour. Starting at 65°F, we’d be below freezing in just under nine hours at this rate, but as the differential drops, the rate that the inside temperature drops will slow down. I'd guess the house would stay above freezing for more than twelve hours even with outside temperatures as cold as we had this morning.
Here’s a plot of the data. The plot looks pretty reasonable with very little code:
import matplotlib.pyplot as plt
plt.figure()
temps_up.plot(subplots = True, figsize = (8.5, 11),
title = u"Heat loss from our house at −35°F",
style = ['bo-', 'ro-', 'ro-', 'ro-', 'go-', 'go-', 'go-'])
plt.legend()
# plt.subplots_adjust(hspace = 0.15)
plt.savefig('downstairs_loss.pdf')
plt.savefig('downstairs_loss.svg')
You’ll notice that even before I came home and replaced the heater, the temperature in the house had started to rise. This is certainly due to solar heating as it was a clear day with more than twelve hours of sunlight.
The plot shows what looks like a relationship between the rate of change inside and the temperature differential between inside and outside, so we’ll test this hypothesis using linear regression.
First, get the data where the temperature in the house was dropping.
cooling = temps_up[temps_up['downstairs_rate'] < 0]
Now run the regression between rate of change and outside temperature:
import pandas as pd
results = pd.ols(y = cooling['downstairs_rate'], x = cooling.ix[:, 'outside'])
results
-------------------------Summary of Regression Analysis-------------------------
Formula: Y ~ <x> + <intercept>
Number of Observations: 38
Number of Degrees of Freedom: 2
R-squared: 0.9214
Adj R-squared: 0.9192
Rmse: 0.2807
F-stat (1, 36): 421.7806, p-value: 0.0000
Degrees of Freedom: model 1, resid 36
-----------------------Summary of Estimated Coefficients------------------------
Variable Coef Std Err t-stat p-value CI 2.5% CI 97.5%
--------------------------------------------------------------------------------
x 0.1397 0.0068 20.54 0.0000 0.1263 0.1530
intercept 1.3330 0.1902 7.01 0.0000 0.9603 1.7057
---------------------------------End of Summary---------------------------------
You can see there’s a very strong positive relationship between the outside temperature and the rate that the inside temperature changes. As it warms outside, the drop in inside temperature slows.
The real relationship is more likely to be related to the differential between inside and outside. In this case, the relationship isn’t quite as strong. I suspect that the heat from the sun is confounding the analysis.
results = pd.ols(y = cooling['downstairs_rate'], x = cooling.ix[:, 'downstairs_diff'])
results
-------------------------Summary of Regression Analysis-------------------------
Formula: Y ~ <x> + <intercept>
Number of Observations: 38
Number of Degrees of Freedom: 2
R-squared: 0.8964
Adj R-squared: 0.8935
Rmse: 0.3222
F-stat (1, 36): 311.5470, p-value: 0.0000
Degrees of Freedom: model 1, resid 36
-----------------------Summary of Estimated Coefficients------------------------
Variable Coef Std Err t-stat p-value CI 2.5% CI 97.5%
--------------------------------------------------------------------------------
x -0.1032 0.0058 -17.65 0.0000 -0.1146 -0.0917
intercept 6.6537 0.5189 12.82 0.0000 5.6366 7.6707
---------------------------------End of Summary---------------------------------
con.close()
I’m not sure how much information I really got out of this, but I am pleasantly surprised that the house held it’s heat as well as it did even with the very cold temperatures. It might be interesting to intentionally turn off the heater in the middle of winter and examine these relationship for a longer period and without the influence of the sun.
And I’ve enjoyed learning a new set of tools for data analysis. Thanks to my friend Ryan for recommending them.
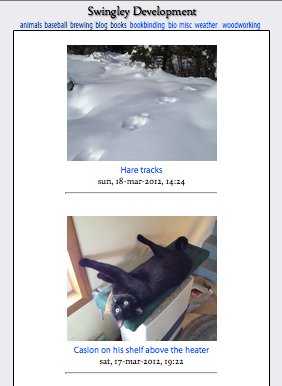
A week ago I set up a Tumblr site with the idea I’d post photos on there, hopefully at least once a day. Sort of a photo-based microblog. After a week of posting stuff I realized it would be really easy to set something like this up on my own site. It works like this:
- Email myself a photo where the subject line has a keyword in it that procmail recognizes, sending the email off to a Python script.
- The Python script processes the email, extracting the photo name and caption from the text portion of the email, rotates and resizes the photo, and saves it in a place accessable from my web server. The photo metadata (size, when the photo was taken, caption and path) is stored in a database.
- A Django app generates the web page from the data in the database.
There are a few tricky bits here. First is handling the rotation of the photos. At least with my phone, the image data is always stored in landscape format, but there’s an EXIF tag that indicates how the data should be rotated for display. So I read that tag and rotate appropriately, using the Python Imaging Library (PIL):
import StringIO
import Image
import ExifTags
orientation_key = 274
if orientation_key in exif:
orientation = exif[orientation_key]
if orientation == 3:
image_data = image_data.rotate(180, expand = True)
elif orientation == 6:
image_data = image_data.rotate(270, expand = True)
elif orientation == 8:
image_data = image_data.rotate(90, expand = True)
For simplicity, I hard coded the orientation_key above, but it’s probably better to get the value from the ExifTags library. That can be done using this list comprehension:
orientation_key = [key for key, value in \
ExifTags.TAGS.iteritems() if value == 'Orientation'][0]
Resizing the image is relatively easy:
(x, y) = image_data.size
if x > y:
if x > 600:
image_600 = image_data.resize(
(600, int(round(600 / float(x) * y))),
Image.ANTIALIAS
)
else:
image_600 = image_data
else:
if y > 600:
image_600 = image_data.resize(
(int(round(600 / float(y) * x)), 600),
Image.ANTIALIAS
)
else:
image_600 = image_data
And the whole thing is wrapped up in the code that parses the pieces of the email message:
import email
msg = email.message_from_file(sys.stdin)
headers = msg.items()
body = []
for part in msg.walk():
if part.get_content_maintype() == 'multipart':
continue
content_type = part.get_content_type()
if content_type == "image/jpeg":
image_data = Image.open(StringIO.StringIO(
part.get_payload(decode = True)
))
elif content_type == "text/plain":
charset = get_charset(part, get_charset(msg))
text = unicode(part.get_payload(decode = True), charset, "replace")
body.append(text)
body = u"\n".join(body).strip()
The get_charset function is:
def get_charset(message, default="ascii"):
"""Get the message charset"""
if message.get_content_charset():
return message.get_content_charset()
if message.get_charset():
return message.get_charset()
return default
Once these pieces are wrapped together, called via procmail, and integrated into Django, it looks like this: photolog. There’s also a link to it in the upper right sidebar of this blog if you’re viewing this page in a desktop web browser.